- PROGRAMMATION MATHÉMATIQUE
- PROGRAMMATION MATHÉMATIQUELa programmation mathématique consiste à chercher, parmi tous les points x vérifiant certaines conditions du type:
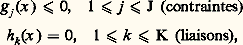 celui ou ceux qui rendent minimal (ou maximal, suivant le cas) un certain critère f (x ), qui sera interprété comme un gain dans le premier cas (et comme un coût dans le second). Quand la variable x est de dimension finie, et que ses composantes (x 1, ..., x N) ne peuvent prendre que des valeurs entières, on parle de programmation en nombres entiers; quand elle est continue, c’est-à-dire quand x décrit Rn ou un autre espace vectoriel, on parle de programmation linéaire, convexe ou non convexe suivant les propriétés des fonctions f , gj et hk . Enfin, la variable x peut avoir une structure, c’est-à-dire se présenter comme une fonction d’autres variables plus primitives, notamment le temps; on emploie alors la programmation dynamique.La programmation mathématique peut donc se définir comme l’analyse numérique des problèmes d’optimisation et de contrôle. Elle a eu une grande importance historique, car à une époque où les moyens de calcul étaient loin d’être ce qu’ils sont devenus, seules des méthodes numériques très performantes pouvaient faire le lien entre la théorie et la pratique, c’est-à-dire démontrer aux utilisateurs la pertinence des modèles adoptés par les chercheurs, et alimenter ceux-ci en problèmes concrets. C’est grâce à la programmation mathématique que la culture scientifique a pour la première fois pénétré la gestion des entreprises: ce qu’on a appelé la recherche opérationnelle n’est qu’un ensemble d’outils de programmation mathématique.Aujourd’hui, la programmation mathématique ne peut plus être séparée du reste de l’analyse numérique. Cette évolution est due au succès même de la discipline et à la banalisation du concept d’optimisation: il n’y a plus guère de problème pratique, numérique ou même informatique, où, d’une manière ou d’une autre, on ne cherche à minimiser quelque chose. L’avenir est commandé par l’augmentation exponentielle et régulière de la puissance de calcul et par la banalisation de l’outil informatique, grâce à la convivialité accrue des logiciels et à la généralisation des stations de travail individuelles. L’analyse numérique devient inséparable de l’informatique: on ne peut plus concevoir un algorithme sans savoir sur quel ordinateur il va être traité. Le calcul vectoriel, parallèle ou en réseau, n’en est encore qu’à ses débuts et on peut en attendre de très grands progrès.1. La programmation en nombres entiersIl s’agit de maximiser une fonction f (x ) sur un ensemble fini X. Bien souvent, cet ensemble a une structure naturelle, par exemple une structure de graphe, ou de réseau: chaque point de X a alors un certain nombre de voisins, et il existe une procédure naturelle, étant donné un point, pour explorer tous ses voisins.La première idée consiste alors à partir d’un point initial x 0 捻 X, à aller chercher ses voisins et, de proche en proche, de voisin en voisin, à explorer l’ensemble X tout entier. Quand on aura visité tous les points, on aura trouvé celui qui maximise le critère retenu. Malheureusement, dans tous les cas pratiques, les procédures de ce genre sont inapplicables, car on se heurte au mur de la dimension.À titre d’exemple, on estime que le nombre de particules élémentaires que contient l’Univers connu est de l’ordre de 10100. Considérons maintenant un problème classique de programmation en nombres entiers: un voyageur de commerce doit visiter N villes, et il souhaite déterminer l’ordre de visite de manière à minimiser la distance parcourue. Le nombre d’itinéraires possibles est alors de N, et, dès N = 32, on tombe sur des nombres de l’ordre de 10100; on conçoit que l’énumération pure et simple des possibilités et leur comparaison directe soient exclues, donc qu’il faille trouver une autre méthode.La théorie des graphes a apporté à la résolution de ces questions une contribution importante. Ces dernières années, la physique a été également une source d’inspiration, avec les méthodes dites de recuit simulé. Il s’agit, pour l’essentiel, de méthodes de descente, mais avec l’introduction d’une composante aléatoire. On part d’un point x 0 捻 X et on cherche, parmi ses voisins, celui qui minimise le critère: c’est un nouveau point x 1 捻 X, et on recommence. En procédant de cette manière, on va arriver à un point x 捻 X qui sera meilleur que tous ses voisins 漣 mais qui ne sera peut-être pas le meilleur dans l’absolu, car il se peut qu’ailleurs dans X, fort loin de x , il y ait un point qui fasse mieux. Pour augmenter les chances que le point d’arrivée x soit un minimum global et pas seulement un minimum local, on autorisera, à chaque étape n , des déplacements dans des directions qui font augmenter, et non baisser, le critère. Ces déplacements devront avoir lieu avec une probabilité pn0: au début, ils sont donc fréquents, ce qui permet au point xn d’explorer l’ensemble du système, avant de se stabiliser dans une région où, pn devenant alors petit, la minimisation prend le dessus.2. La programmation linéaireUn programme linéaire type s’écrira:
celui ou ceux qui rendent minimal (ou maximal, suivant le cas) un certain critère f (x ), qui sera interprété comme un gain dans le premier cas (et comme un coût dans le second). Quand la variable x est de dimension finie, et que ses composantes (x 1, ..., x N) ne peuvent prendre que des valeurs entières, on parle de programmation en nombres entiers; quand elle est continue, c’est-à-dire quand x décrit Rn ou un autre espace vectoriel, on parle de programmation linéaire, convexe ou non convexe suivant les propriétés des fonctions f , gj et hk . Enfin, la variable x peut avoir une structure, c’est-à-dire se présenter comme une fonction d’autres variables plus primitives, notamment le temps; on emploie alors la programmation dynamique.La programmation mathématique peut donc se définir comme l’analyse numérique des problèmes d’optimisation et de contrôle. Elle a eu une grande importance historique, car à une époque où les moyens de calcul étaient loin d’être ce qu’ils sont devenus, seules des méthodes numériques très performantes pouvaient faire le lien entre la théorie et la pratique, c’est-à-dire démontrer aux utilisateurs la pertinence des modèles adoptés par les chercheurs, et alimenter ceux-ci en problèmes concrets. C’est grâce à la programmation mathématique que la culture scientifique a pour la première fois pénétré la gestion des entreprises: ce qu’on a appelé la recherche opérationnelle n’est qu’un ensemble d’outils de programmation mathématique.Aujourd’hui, la programmation mathématique ne peut plus être séparée du reste de l’analyse numérique. Cette évolution est due au succès même de la discipline et à la banalisation du concept d’optimisation: il n’y a plus guère de problème pratique, numérique ou même informatique, où, d’une manière ou d’une autre, on ne cherche à minimiser quelque chose. L’avenir est commandé par l’augmentation exponentielle et régulière de la puissance de calcul et par la banalisation de l’outil informatique, grâce à la convivialité accrue des logiciels et à la généralisation des stations de travail individuelles. L’analyse numérique devient inséparable de l’informatique: on ne peut plus concevoir un algorithme sans savoir sur quel ordinateur il va être traité. Le calcul vectoriel, parallèle ou en réseau, n’en est encore qu’à ses débuts et on peut en attendre de très grands progrès.1. La programmation en nombres entiersIl s’agit de maximiser une fonction f (x ) sur un ensemble fini X. Bien souvent, cet ensemble a une structure naturelle, par exemple une structure de graphe, ou de réseau: chaque point de X a alors un certain nombre de voisins, et il existe une procédure naturelle, étant donné un point, pour explorer tous ses voisins.La première idée consiste alors à partir d’un point initial x 0 捻 X, à aller chercher ses voisins et, de proche en proche, de voisin en voisin, à explorer l’ensemble X tout entier. Quand on aura visité tous les points, on aura trouvé celui qui maximise le critère retenu. Malheureusement, dans tous les cas pratiques, les procédures de ce genre sont inapplicables, car on se heurte au mur de la dimension.À titre d’exemple, on estime que le nombre de particules élémentaires que contient l’Univers connu est de l’ordre de 10100. Considérons maintenant un problème classique de programmation en nombres entiers: un voyageur de commerce doit visiter N villes, et il souhaite déterminer l’ordre de visite de manière à minimiser la distance parcourue. Le nombre d’itinéraires possibles est alors de N, et, dès N = 32, on tombe sur des nombres de l’ordre de 10100; on conçoit que l’énumération pure et simple des possibilités et leur comparaison directe soient exclues, donc qu’il faille trouver une autre méthode.La théorie des graphes a apporté à la résolution de ces questions une contribution importante. Ces dernières années, la physique a été également une source d’inspiration, avec les méthodes dites de recuit simulé. Il s’agit, pour l’essentiel, de méthodes de descente, mais avec l’introduction d’une composante aléatoire. On part d’un point x 0 捻 X et on cherche, parmi ses voisins, celui qui minimise le critère: c’est un nouveau point x 1 捻 X, et on recommence. En procédant de cette manière, on va arriver à un point x 捻 X qui sera meilleur que tous ses voisins 漣 mais qui ne sera peut-être pas le meilleur dans l’absolu, car il se peut qu’ailleurs dans X, fort loin de x , il y ait un point qui fasse mieux. Pour augmenter les chances que le point d’arrivée x soit un minimum global et pas seulement un minimum local, on autorisera, à chaque étape n , des déplacements dans des directions qui font augmenter, et non baisser, le critère. Ces déplacements devront avoir lieu avec une probabilité pn0: au début, ils sont donc fréquents, ce qui permet au point xn d’explorer l’ensemble du système, avant de se stabiliser dans une région où, pn devenant alors petit, la minimisation prend le dessus.2. La programmation linéaireUn programme linéaire type s’écrira: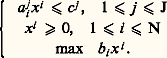 La programmation linéaire est le point de départ historique de la programmation mathématique, avec les travaux de Dantzig, Kuhn et Tucker entre 1945 et 1950. Elle reste le domaine où elle a enregistré ses plus grands succès.Pour bien comprendre la difficulté du problème, commençons par noter que le domaine permis, c’est-à-dire l’ensemble des points qui satisfont les contraintes, est ici un polyèdre de RN: toutes les contraintes sont des fonctions linéaires des variables xj , et le domaine permis est donc délimité par un certain nombre d’hyperplans qui constituent ses faces. Ces faces déterminent un certain nombre de sommets, et comme le critère est lui-même linéaire, le maximum devra être atteint sur un de ces sommets. Il suffit donc d’explorer un à un tous les sommets du polyèdre pour être sûr de trouver le sommet maximisant, c’est-à-dire la solution du problème (P).Malheureusement, on se trouve encore confronté au mur de la dimension. Le nombre de sommets du cube de côté 1 dans R400 est de l’ordre de 10100, ce qui nous limiterait à N 麗麗 400; or on est capable de traiter des problèmes comportant des dizaines de milliers de variables. C’est dire combien les méthodes actuelles sont performantes.La première d’entre elles a été l’algorithme du simplexe. Il permet de construire un chemin qui saute d’un sommet du polyèdre à l’autre, en améliorant le critère à chaque pas, souvent de manière considérable, puisque certains travaux, dus notamment à Smale, ont montré qu’il résout en temps polynomial (par rapport au nombre de contraintes et de variables) la plupart des problèmes de programmation linéaire. Mais en 1978, à la surprise générale, Kachian indiquait une méthode plus performante que l’algorithme du simplexe. L’idée de Kachian, améliorée par Karmarkar, est à la base de tous les algorithmes modernes; à la différence du simplexe, ces algorithmes ne se promènent pas de sommet en sommet, mais acceptent de traverser le polyèdre par l’intérieur.3. La programmation convexeOn considère le problème:
La programmation linéaire est le point de départ historique de la programmation mathématique, avec les travaux de Dantzig, Kuhn et Tucker entre 1945 et 1950. Elle reste le domaine où elle a enregistré ses plus grands succès.Pour bien comprendre la difficulté du problème, commençons par noter que le domaine permis, c’est-à-dire l’ensemble des points qui satisfont les contraintes, est ici un polyèdre de RN: toutes les contraintes sont des fonctions linéaires des variables xj , et le domaine permis est donc délimité par un certain nombre d’hyperplans qui constituent ses faces. Ces faces déterminent un certain nombre de sommets, et comme le critère est lui-même linéaire, le maximum devra être atteint sur un de ces sommets. Il suffit donc d’explorer un à un tous les sommets du polyèdre pour être sûr de trouver le sommet maximisant, c’est-à-dire la solution du problème (P).Malheureusement, on se trouve encore confronté au mur de la dimension. Le nombre de sommets du cube de côté 1 dans R400 est de l’ordre de 10100, ce qui nous limiterait à N 麗麗 400; or on est capable de traiter des problèmes comportant des dizaines de milliers de variables. C’est dire combien les méthodes actuelles sont performantes.La première d’entre elles a été l’algorithme du simplexe. Il permet de construire un chemin qui saute d’un sommet du polyèdre à l’autre, en améliorant le critère à chaque pas, souvent de manière considérable, puisque certains travaux, dus notamment à Smale, ont montré qu’il résout en temps polynomial (par rapport au nombre de contraintes et de variables) la plupart des problèmes de programmation linéaire. Mais en 1978, à la surprise générale, Kachian indiquait une méthode plus performante que l’algorithme du simplexe. L’idée de Kachian, améliorée par Karmarkar, est à la base de tous les algorithmes modernes; à la différence du simplexe, ces algorithmes ne se promènent pas de sommet en sommet, mais acceptent de traverser le polyèdre par l’intérieur.3. La programmation convexeOn considère le problème: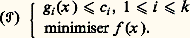 Les gi et f sont des fonctions convexes sur Rn . L’ensemble permis est alors une partie convexe de Rn , mais ce n’est plus un polyèdre. En général, le minimum sera atteint en un point du bord.Le Lagrangien du problème est la fonction L sur Rn 憐 Rk + définie par:
Les gi et f sont des fonctions convexes sur Rn . L’ensemble permis est alors une partie convexe de Rn , mais ce n’est plus un polyèdre. En général, le minimum sera atteint en un point du bord.Le Lagrangien du problème est la fonction L sur Rn 憐 Rk + définie par: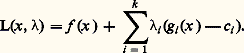 Sous certaines conditions, dites de qualification des contraintes, par exemple qu’il existe un point じ tel que gi ( じ ) 麗 ci pour tout i , le point 異 résout (face=F0021 戮) si et seulement si on peut trouver 漣 捻 Rk + tel que:
Sous certaines conditions, dites de qualification des contraintes, par exemple qu’il existe un point じ tel que gi ( じ ) 麗 ci pour tout i , le point 異 résout (face=F0021 戮) si et seulement si on peut trouver 漣 捻 Rk + tel que: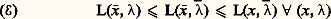 La relation (face=F0021 劉) exprime que ( 異 , 漣) est un point-selle du Lagrangien L(x ,) sur l’ensemble Rn 憐 Rk +. Elle s’écrit aussi:
La relation (face=F0021 劉) exprime que ( 異 , 漣) est un point-selle du Lagrangien L(x ,) sur l’ensemble Rn 憐 Rk +. Elle s’écrit aussi: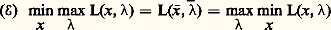 L’expressionmin max L(x ,) vaut f (x ) xsi gi (x ) 諒 ci , et + 秊 sinon, si bien que le membre de gauche redonne le problème (face=F0021 戮). Le membre de droite donne un autre programme convexe, le programme dual, dont 漣 est solution:
L’expressionmin max L(x ,) vaut f (x ) xsi gi (x ) 諒 ci , et + 秊 sinon, si bien que le membre de gauche redonne le problème (face=F0021 戮). Le membre de droite donne un autre programme convexe, le programme dual, dont 漣 est solution: La résolution de (face=F0021 戮), c’est-à-dire la connaissance des multiplicateurs 漣1, ..., 漣k , trivialise le problème (face=F0021 戮), qui se ramène à minimiser sur Rn la fonction L(face=F0019 練, 漣), les contraintes ayant disparu.Signalons un cas particulier important. On rencontre souvent en économie des problèmes de répartition du type suivant:
La résolution de (face=F0021 戮), c’est-à-dire la connaissance des multiplicateurs 漣1, ..., 漣k , trivialise le problème (face=F0021 戮), qui se ramène à minimiser sur Rn la fonction L(face=F0019 練, 漣), les contraintes ayant disparu.Signalons un cas particulier important. On rencontre souvent en économie des problèmes de répartition du type suivant: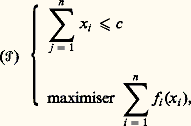 où les fonctions fi : RdR 聆+ 秊sont convexes, et valent + 秊 hors de l’orthant positif Rd + (ce qui revient à introduire les contraintes x i j 閭 0 pour tout i et j ). Le Lagrangien du problème s’écrit:
où les fonctions fi : RdR 聆+ 秊sont convexes, et valent + 秊 hors de l’orthant positif Rd + (ce qui revient à introduire les contraintes x i j 閭 0 pour tout i et j ). Le Lagrangien du problème s’écrit: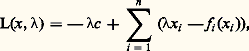 et la connaissance du multiplicateur 漣 permet de décomposer le problème initial en n problèmes individuels:
et la connaissance du multiplicateur 漣 permet de décomposer le problème initial en n problèmes individuels: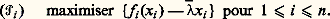 L’interprétation économique est la suivante. Il s’agit de répartir des biens en quantité c 捻 Rd entre n agents – succursales, usines, etc. Si l’agent i se voit allouer la quantité xi , il rapportera à l’entreprise le profit fi (xi ) – en ventes, production, etc.Le problème (face=F0021 戮) est le problème du planificateur: trouver la répartition optimale. Si les 異i sont connus, ils peuvent être assignés individuellement aux agents sous forme de quotas. Mais le même objectif peut être atteint par la connaissance du multiplicateur 漣 捻 Rd +; il suffit de laisser les agents s’approvisionner librement, en leur imposant de maximiser leur profit, compte tenu du fait que les fournitures leur seront facturées au «prix interne» 漣. C’est ce qu’on appelle la décentralisation par les prix. L’avantage principal est que la collection des quotas 異i représente nd nombres, alors que le système de prix internes 漣 n’en représente que d .Un mot pour terminer des méthodes numériques. Elles sont essentiellement de deux types: les méthodes directes et les méthodes de dualité.Les méthodes directes consistent à travailler directement sur le problème primal. On cherche en général un algorithme de descente, c’est-à-dire que la suite (xn ) engendrée à partir de x 0 vérifie f (x n +1) 諒 f (xn ) pour tout n . La plus classique est la méthode du gradient projeté; elle utilise le fait que tout point de l’espace a une projection bien définie sur toute partie convexe. On projette le gradient f (xn ) sur le cône tangent en xn , on fait un pas dans cette direction, ce qui donne yn , et on projette yn sur l’ensemble permis, ce qui donne x n +1. La mise au point de méthodes analogues dans le cas où f n’est pas différentiable est un domaine de recherches fort actif.Les autres méthodes consistent à travailler simultanément sur le problème et son dual. La plus classique est la méthode d’Uzawa, qui consiste à chercher le point-selle du Lagrangien L(x ,): à chaque itération partant de (xn ,n ), on fait un pas dans la direction des x décroissants, ce qui donne (x n +1,n ), et un pas dans la direction des croissants, ce qui donne (x n +1,n + 1).4. La programmation non convexeDans le cas où les fonctions en jeu ne sont plus convexes, la situation est beaucoup moins claire: les conditions nécessaires d’optimalité ne sont plus suffisantes, et il n’y a nul moyen de distinguer un minimum local d’un minimum global. Les méthodes numériques ne peuvent déceler que des minimums locaux, et l’utilisateur ne saura donc jamais si la solution qu’il a trouvée est bien la meilleure. Cela dit, dans la plupart des cas, il se contentera qu’elle soit bonne, ou meilleure que ce qu’il faisait jusque-là.De ce point de vue, la programmation non convexe a beaucoup de parenté avec la programmation en nombres entiers, et d’ailleurs certaines idées provenant de celle-ci peuvent être utilisées avec succès. Ainsi, les méthodes de descente peuvent être considérablement améliorées si on introduit un élément aléatoire, comme dans le recuit simulé.Plus précisément, la méthode la plus simple pour minimiser une fonction f (x ) sur RN consiste à descendre suivant le gradient, c’est-à-dire à utiliser un algorithme du type xn + 1 = xn 漣 rnf (xn ), le choix du pas rn dépendant de l’algorithme choisi. L’inconvénient de ces méthodes est qu’elles aboutissent sur un point dont on ne saura jamais s’il s’agit d’un minimum local ou d’un minimum global. Pour augmenter les chances qu’il s’agisse bien d’un minimum global, on introduira au second membre une composante aléatoire, qui fera croître f , c’est-à-dire que l’on aura f (xn + 1) 礪 f (xn ), avec une probabilité pn tendant vers zéro à mesure que n tend vers l’infini. Ainsi, on donne au point xn la possibilité d’explorer tout l’espace avant de se mettre à descendre vers un minimum.Une autre idée intéressante, purement déterministe celle-là, consiste à paramétrer le problème. Si on veut, par exemple, chercher les racines d’un polynôme, c’est-à-dire résoudre P(z ) = 0 dans le plan complexe C, avec:
L’interprétation économique est la suivante. Il s’agit de répartir des biens en quantité c 捻 Rd entre n agents – succursales, usines, etc. Si l’agent i se voit allouer la quantité xi , il rapportera à l’entreprise le profit fi (xi ) – en ventes, production, etc.Le problème (face=F0021 戮) est le problème du planificateur: trouver la répartition optimale. Si les 異i sont connus, ils peuvent être assignés individuellement aux agents sous forme de quotas. Mais le même objectif peut être atteint par la connaissance du multiplicateur 漣 捻 Rd +; il suffit de laisser les agents s’approvisionner librement, en leur imposant de maximiser leur profit, compte tenu du fait que les fournitures leur seront facturées au «prix interne» 漣. C’est ce qu’on appelle la décentralisation par les prix. L’avantage principal est que la collection des quotas 異i représente nd nombres, alors que le système de prix internes 漣 n’en représente que d .Un mot pour terminer des méthodes numériques. Elles sont essentiellement de deux types: les méthodes directes et les méthodes de dualité.Les méthodes directes consistent à travailler directement sur le problème primal. On cherche en général un algorithme de descente, c’est-à-dire que la suite (xn ) engendrée à partir de x 0 vérifie f (x n +1) 諒 f (xn ) pour tout n . La plus classique est la méthode du gradient projeté; elle utilise le fait que tout point de l’espace a une projection bien définie sur toute partie convexe. On projette le gradient f (xn ) sur le cône tangent en xn , on fait un pas dans cette direction, ce qui donne yn , et on projette yn sur l’ensemble permis, ce qui donne x n +1. La mise au point de méthodes analogues dans le cas où f n’est pas différentiable est un domaine de recherches fort actif.Les autres méthodes consistent à travailler simultanément sur le problème et son dual. La plus classique est la méthode d’Uzawa, qui consiste à chercher le point-selle du Lagrangien L(x ,): à chaque itération partant de (xn ,n ), on fait un pas dans la direction des x décroissants, ce qui donne (x n +1,n ), et un pas dans la direction des croissants, ce qui donne (x n +1,n + 1).4. La programmation non convexeDans le cas où les fonctions en jeu ne sont plus convexes, la situation est beaucoup moins claire: les conditions nécessaires d’optimalité ne sont plus suffisantes, et il n’y a nul moyen de distinguer un minimum local d’un minimum global. Les méthodes numériques ne peuvent déceler que des minimums locaux, et l’utilisateur ne saura donc jamais si la solution qu’il a trouvée est bien la meilleure. Cela dit, dans la plupart des cas, il se contentera qu’elle soit bonne, ou meilleure que ce qu’il faisait jusque-là.De ce point de vue, la programmation non convexe a beaucoup de parenté avec la programmation en nombres entiers, et d’ailleurs certaines idées provenant de celle-ci peuvent être utilisées avec succès. Ainsi, les méthodes de descente peuvent être considérablement améliorées si on introduit un élément aléatoire, comme dans le recuit simulé.Plus précisément, la méthode la plus simple pour minimiser une fonction f (x ) sur RN consiste à descendre suivant le gradient, c’est-à-dire à utiliser un algorithme du type xn + 1 = xn 漣 rnf (xn ), le choix du pas rn dépendant de l’algorithme choisi. L’inconvénient de ces méthodes est qu’elles aboutissent sur un point dont on ne saura jamais s’il s’agit d’un minimum local ou d’un minimum global. Pour augmenter les chances qu’il s’agisse bien d’un minimum global, on introduira au second membre une composante aléatoire, qui fera croître f , c’est-à-dire que l’on aura f (xn + 1) 礪 f (xn ), avec une probabilité pn tendant vers zéro à mesure que n tend vers l’infini. Ainsi, on donne au point xn la possibilité d’explorer tout l’espace avant de se mettre à descendre vers un minimum.Une autre idée intéressante, purement déterministe celle-là, consiste à paramétrer le problème. Si on veut, par exemple, chercher les racines d’un polynôme, c’est-à-dire résoudre P(z ) = 0 dans le plan complexe C, avec: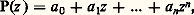 on pourra considérer le polynôme plus général:
on pourra considérer le polynôme plus général: Pour t = 1, on retrouve le polynôme initial P0 = P. Pour t = 0, on trouve le polynôme P1(z ) = 1 + z + ... + zn , dont toutes les racines sont connues; ce sont les racines (n + 1)-ièmes de l’unité, à l’exception de 1. Si, maintenant, on arrive à suivre par continuité les racines de l’équation Pt (z ) = 0, depuis t = 0, où elles sont connues, jusqu’à t = 1, où elles ne le sont pas, on aura bel et bien résolu le problème. C’est l’idée de base des méthodes d’homotopie, ou de Newton.5. La programmation dynamiqueCertains problèmes d’optimisation ont une structure temporelle: il s’agit de piloter un système en choisissant à chaque instant les valeurs que prendront une ou plusieurs variables de décision, appelées les contrôles. Les contrôles déterminent l’état x (t ) du système à chaque instant t , et il s’agit de minimiser un certain critère dépendant par exemple de l’état final x (T), soit f (x (T)). Pour résoudre ce genre de problème, la méthode est la programmation dynamique, dont la formulation explicite dans ce contexte est due à Bellman, même si elle était déjà connue et utilisée en calcul des variations (équation de Hamilton-Jacobi, méthode de Carathéodory).L’idée est la suivante. Pour tout instant t , et tout état x , on se demande comment on ferait si, au lieu de partir de la situation initiale imposée x 0 à l’instant fixé t = 0, on partait de x à l’instant t . Le nouveau problème n’est bien entendu pas plus facile que le premier, mais sa réponse (inconnue) donnerait au critère f utilisé une valeur optimale V(x , t ), et cette fonction (inconnue) V vérifie une équation qui, elle, est connue: c’est l’équation de Bellman. La résolution de cette équation permet de trouver le contrôle optimal pour toutes les conditions initiales, et en particulier celle qui nous a été imposée.Dans les années 1990, des progrès théoriques importants ont été accomplis par P. L. Lions et M. Crandall, qui ont donné une méthode très générale de résolution de l’équation de Bellman. Cette méthode est donc promise à un très grand avenir.
Pour t = 1, on retrouve le polynôme initial P0 = P. Pour t = 0, on trouve le polynôme P1(z ) = 1 + z + ... + zn , dont toutes les racines sont connues; ce sont les racines (n + 1)-ièmes de l’unité, à l’exception de 1. Si, maintenant, on arrive à suivre par continuité les racines de l’équation Pt (z ) = 0, depuis t = 0, où elles sont connues, jusqu’à t = 1, où elles ne le sont pas, on aura bel et bien résolu le problème. C’est l’idée de base des méthodes d’homotopie, ou de Newton.5. La programmation dynamiqueCertains problèmes d’optimisation ont une structure temporelle: il s’agit de piloter un système en choisissant à chaque instant les valeurs que prendront une ou plusieurs variables de décision, appelées les contrôles. Les contrôles déterminent l’état x (t ) du système à chaque instant t , et il s’agit de minimiser un certain critère dépendant par exemple de l’état final x (T), soit f (x (T)). Pour résoudre ce genre de problème, la méthode est la programmation dynamique, dont la formulation explicite dans ce contexte est due à Bellman, même si elle était déjà connue et utilisée en calcul des variations (équation de Hamilton-Jacobi, méthode de Carathéodory).L’idée est la suivante. Pour tout instant t , et tout état x , on se demande comment on ferait si, au lieu de partir de la situation initiale imposée x 0 à l’instant fixé t = 0, on partait de x à l’instant t . Le nouveau problème n’est bien entendu pas plus facile que le premier, mais sa réponse (inconnue) donnerait au critère f utilisé une valeur optimale V(x , t ), et cette fonction (inconnue) V vérifie une équation qui, elle, est connue: c’est l’équation de Bellman. La résolution de cette équation permet de trouver le contrôle optimal pour toutes les conditions initiales, et en particulier celle qui nous a été imposée.Dans les années 1990, des progrès théoriques importants ont été accomplis par P. L. Lions et M. Crandall, qui ont donné une méthode très générale de résolution de l’équation de Bellman. Cette méthode est donc promise à un très grand avenir.
Encyclopédie Universelle. 2012.